その仕組みとは
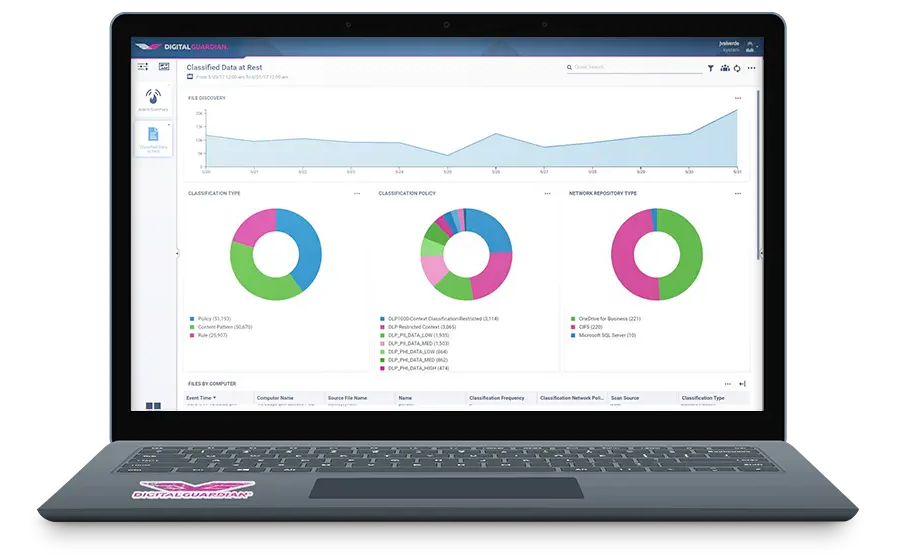
コンテンツ、コンテキスト、そしてユーザの分類。Digital Guardian Data Classification では、重要データを自動的に検索、特定してタグを付与することで分類し、データの処理方法を決定します。 コンテンツ(特定文字列や構造化データの認識)、およびコンテキスト (重要データの性質や、保存場所、また利用アプリケーション等の認識)に基づいたデータの自動分類から、ユーザによる手動分類までさまざまな分類方法に対応しています。
お客様は、重要なデータがどのように使用されているかを把握することで適切に制御できるようになり、コンプライアンス対応、IP(知的財産)の保護等を効率的に実現することが可能となります。
主な利点
セキュリティ効率の向上
セキュリティ施策実行を促進
非重要データの管理負担の低減
DIGITAL GUARDIAN が選ばれる理由

最も幅広く、最も正確な重要データ分類ソリューション
Digital Guardian DLP には、完全に自動化された分類から手動によるユーザー分類まで、あらゆる分類機能が組み込まれています。 コンテキスト ベースの分類を使用すると、セキュリティポリシーを指定せずとも重要データを自動的に特定し、分類することができます。 また、コンテンツ ベースの自動ファイル調査機能においても、重要データの特定、タグ付けによる分類、フィンガープリンティングによって誤検出を最小限に抑えます。 更に、ユーザ分類機能を使用するとビジネス要求に基づいて、ユーザが重要データを自ら分類することができます。 それぞれの機能を個別に、または組み合わせて使用することで、最も包括的なデータ分類ソリューションが実現します。

Gartner 社が No. 1 に選んだIP(知的財産)保護テクノロジー
Digital Guardian のコンテキスト ベースの分類機能は、IP(知的財産)などの非構造化データをユーザ、保存箇所、およびデータ作成アプリケーション等の情報に基づいて適切に分類できる唯一のソリューションです。 コンテンツベースと、コンテキストベースの分類方法を組み合わせることで、お客様は、コンプライアンス要件、特定文字列や個人情報、またデータタイプ、および作成ユーザ等、あらゆる要件に従ってデータを分類し、タグ付けすることが可能となります。 これがGartner 社によってNo.1知財保護ソリューションに選定された理由の 1 つです。

より正確な データ漏洩防止と脅威検知 / 対応
Digital Guardian Data Classification は脅威認識型データ保護プラットフォームに統合されています。 分類されたお客様の重要データは、漏洩防止、および脅威検知 / 対応の両方の目的で使用できるようになります。 データの重要性をアラート優先順位に組み込むことができるため、インシデント対応の効率性が向上します。