In my previous blog I mentioned the top 5 challenges that organizations subject to GDPR regulations will face:
- The EU Resident is The New Data Owner
- Confidentiality & Sensitive Data Protection
- Notification Requirement
- Privacy by Design & Default
- Data Protection Officer
In this blog I will dive into the top challenge organizations throughout the globe will face when GDPR goes live in the spring of 2018 – the vastly shifted power balance. Prior to GDPR data subjects had a certain set of rights, but nothing quite like what the GDPR will bestow upon these same data subjects. In a post-GDPR world, the EU resident is the new data owner, and this will pose some obstacles for many organizations.
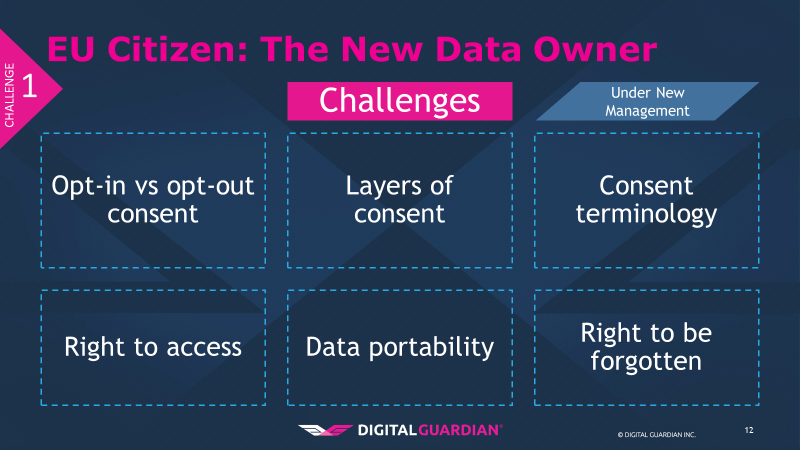
First are the revisions to consent by the data subjects to the processing of their personal information. The concept of implied opt-in is essentially forbidden with GDPR. Pre-ticked boxes or other silent acceptance may no longer be employed to gain consent. Data subjects must explicitly opt-in, and this consent must be “freely given, specific, informed and unambiguous.”
Second is that consent is tiered based on data type; GDPR applies to personal data and sensitive personal data, the latter being more potentially intimate details of who you are. An additional layer of consent is needed for this second layer of information. What is the difference between personal and sensitive personal data?
Personal Data:
“(1) ‘personal data’ means any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person;”
Sensitive Personal Data:
“Processing of personal data revealing racial or ethnic origin, political opinions, religious or philosophical beliefs, or trade union membership, and the processing of genetic data, biometric data for the purpose of uniquely identifying a natural person, data concerning health or data concerning a natural person's sex life or sexual orientation shall be prohibited.”
A third component of this challenge is consent terminology. How many of us have seen an unintelligible consent form that we, perhaps if we had the time, could wade through and make sense of? The beneficiary of this practice is not the data subject, it is the data collector or processor. This practice serves as an attempt to obfuscate the rights you are giving up by consenting. With GDPR in enforcement, consent terminology must be “…in an intelligible and easily accessible form, using clear and plain language.”
Fourth, the right to access. Data subjects can now request confirmation that their data is held and being processed. Under the DPA a fee of £10 was allowed; GDPR bans this fee. This means organizations will bear a cost to fulfill this requirement, and can no longer directly pass the cost along as a disincentive to inquire. Within this right to access is the right to correct the data if it is incorrect.
Fifth, data portability. If I, as a data subject, know you have my information I can request you provide it to me so that it can be used by another data processor. It must be provided to the data subject in a commonly used format to allow easier integration into the new data processor’s system.
Finally, the right to be forgotten. This means a data subject can request that his or her personal data be erased from the processor’s systems and the data processor must respond to these requests without undue delay. This term brings to mind the Ashley Madison breach from 2015 where, as part of the hack it came to light that despite charging patrons $20, they were not fully deleting their records, despite their claims.
Given these challenges, how do organizations proceed? I am going to rely on the People, Process, Technology model to offer suggestions.
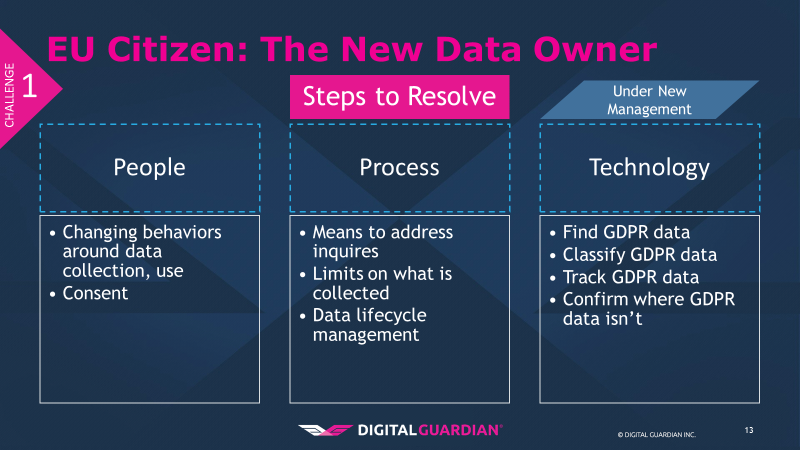
The first component in addressing this challenge is people. The biggest change here is around the behaviors and attitudes of the people within organizations. The people aspect is both simple and complex; the nature to change or resist change varies from organization to organization. For some, this may be an easy process; if your business is accustomed to reinventing itself, then your team may accept the changes far more easily than an entrenched business. I’ve been in a variety of companies ranging from 350k employees to under 50 employees, and I can say there is a range in how well this works.
Consent changes are a key element. The people within the business need to change how they view consent from a hidden and secretive part of the business to a far more user-friendly and forward model, from the opt-in approach to the actual verbiage used.
Next up is the process(es) that these people will need to adopt to make changes systematic and not just a one-time event. The means to address inquiries and requests will be a significant change, as GDPR expects these to be handled “without undue delay.” This means the process cannot be a black hole or these data subjects can cry foul on lack of response.
Another element of the process in overcoming this challenge is putting limits on what is collected. With the rise of big data, data collection has become an exercise in “get as much as you can and we will figure out how to use it later.” Not only does GDPR limit what you can collect to relevant data, complete with a legitimate and defensible tie between collected data and usage, but it incentivizes businesses to limit what they collect. While the data an organization can collect will be restricted, there is an upside to this for organizational security. Limiting what kind and how much user data you collect reduces your attack surface, limits the scope of what an attacker can get, and reduces your data protection costs. From a strictly financial perspective, the less you have, the less you need to protect.
The final process element to overcoming this challenge involves implementing a data lifecycle management process to inventory, classify, track the movement of, and finally dispose of data when it is no longer needed.
Finally, technology. To support what the people do and the processes involved, as well as enforce compliance, a technology backstop is needed. A comprehensive, enterprise-wide data discovery solution is required to locate the data potentially subject to GDPR, whether it lives on laptops, servers, databases, files shares, or in the cloud. Once you have found it, data classification helps to track and control the movement of GDPR data. Organizations rely on three key types of classification 1) content based (what is in the document such as name, date of birth, or address) 2) context based (attributes about the document such as application used or storage location), or 3) user based (the user accessing the file decides what is in the document). A final element of using technology is to leverage the data discovery tools to deem repositories “clean” of GDPR data when, after analysis, no GDPR data is present.
To learn more about the other four top GDPR challenges and the steps required to address them ahead of the May 2018 GDPR deadline, watch our webinar on demand.
Complying with the General Data Protection Regulation requires businesses to have visibility into what data they possess and where it's located.
See how Digital Guardian helps find and protect EU residents’ sensitive, personal data with low overhead.
